13 Análisis de datos: donde la magia (no) ocurre
13.1 No hay magia, hay trabajo
Muchos estudiantes creen que el análisis de datos es el momento mágico donde “los resultados aparecen.” Metes los datos en SPSS, presionas unos botones, y salen tablas con estrellas (asteriscos de significancia estadística). Magia.
No. El análisis de datos es un proceso que requiere decisiones informadas en cada paso. Y esas decisiones dependen de tu pregunta, tu marco teórico, tu diseño y la naturaleza de tus datos. No hay piloto automático. Como dice Andy Field en su ya clásico manual: “SPSS no puede pensar por ti. Si presionas el botón equivocado, obtendrás resultados. Serán resultados incorrectos, pero serán resultados” (Field, 2018).
Este capítulo cubre tanto el análisis cuantitativo como el cualitativo, porque ambos comparten un principio fundamental: se trata de buscar patrones en datos de manera sistemática y transparente. Los datos son diferentes, las técnicas son diferentes, pero la lógica intelectual es la misma: observar con cuidado, clasificar con rigor, e interpretar con honestidad.
13.2 Antes de analizar: limpia tus datos
Esto no es glamoroso, pero es donde se gasta el 60-80% del tiempo real de análisis. No estoy exagerando. Pregúntale a cualquier data scientist y te dirá lo mismo: la limpieza de datos es el trabajo real. El análisis es la parte divertida que ocupa el 20% restante.
Limpiar datos implica:
Revisar valores faltantes (missing values): ¿Cuántos hay? ¿Son aleatorios o sistemáticos? Si todos los que no respondieron la pregunta de ingreso son los más pobres, tienes un sesgo grave. La decisión de cómo manejar los faltantes (eliminar casos, imputar, usar modelos que los toleren) es una decisión de investigación, no una cuestión técnica. Diferentes decisiones pueden llevar a diferentes resultados.
Detectar valores atípicos (outliers): ¿Alguien reportó ganar 999.999? Probablemente es un error de digitación, no un multimillonario. Pero cuidado: no elimines valores atípicos solo porque te incomodan. Un outlier genuino es información valiosa. Un outlier que es error de medición es ruido. Tu trabajo es distinguir.
Verificar consistencia interna: ¿Un respondiente dice tener 15 años y 3 hijos? Posible pero improbable. ¿Alguien dice que no trabaja pero reporta ingresos laborales? Algo no cuadra. Busca inconsistencias lógicas.
Recodificar y transformar variables: Agrupar categorías (quizás no necesitas 15 niveles educativos; quizás con 4 basta), crear índices compuestos (sumar varios ítems para formar una escala), transformar variables sesgadas (logaritmo del ingreso, por ejemplo).
Verificar la calidad de tus instrumentos: Si diseñaste una escala, ¿tiene buena confiabilidad? El Alfa de Cronbach te lo dice, pero tiene limitaciones. Si adaptaste un instrumento de otro contexto, ¿funcionó igual en tu muestra?
AdvertenciaAdvertencia
Regla fundamental: Documenta TODO lo que hagas. Cada transformación, cada decisión, cada eliminación. Si eliminas 47 casos por “inconsistencias,” explica cuáles y por qué. Tu “yo” del futuro (y tus revisores) te lo agradecerán. Wickham y sus colegas han convertido esto en un mantra de la ciencia de datos reproducible: si no está documentado, no sucedió (Wickham et al., 2023).
13.3 Estadística descriptiva: lo básico que muchos ignoran
Antes de correr regresiones sofisticadas, mira tus datos. En serio. Míralos. No de forma metafórica: literal. Haz gráficos. Calcula medias. Cruza tablas. Entiende qué tienes antes de intentar explicarlo.
- Distribución: ¿Cómo se ven tus variables? ¿Son normales, sesgadas, bimodales? Una variable de ingreso en América Latina casi nunca es normal —está sesgada a la derecha, porque pocos ganan mucho y muchos ganan poco. Eso afecta qué tests puedes usar.
- Tendencia central: Media, mediana, moda. ¿Son diferentes? ¿Por qué? Si tu media es 5.000 pero tu mediana es 2.000, tienes una distribución muy sesgada y la media te está engañando.
- Dispersión: Desviación estándar, rango, rango intercuartil. ¿Hay mucha variabilidad? Un programa educativo con efecto promedio de 10 puntos puede significar cosas muy diferentes si la desviación estándar es 5 (casi todos mejoraron) o 50 (algunos mejoraron mucho, otros empeoraron).
- Tablas cruzadas: ¿Cómo se relacionan tus variables principales? Antes de correr una regresión de educación sobre ingreso, cruza educación e ingreso en una tabla simple. ¿La relación es lo que esperabas?
- Gráficos: Histogramas, diagramas de caja (boxplots), diagramas de dispersión (scatterplots). Un buen gráfico te puede revelar patrones que ninguna tabla muestra.
La estadística descriptiva no es el “paso previo” al análisis real. Es análisis. Muchos de los hallazgos más importantes de las ciencias sociales son fundamentalmente descriptivos. La distribución del ingreso, la composición demográfica de un país, la tasa de feminicidios: estos números descriptivos importan enormemente. No todo requiere una regresión.
13.4 Análisis cuantitativo: la caja de herramientas estadísticas
13.4.1 Correlación
Mide la fuerza y dirección de la relación lineal entre dos variables. Va de -1 a 1.
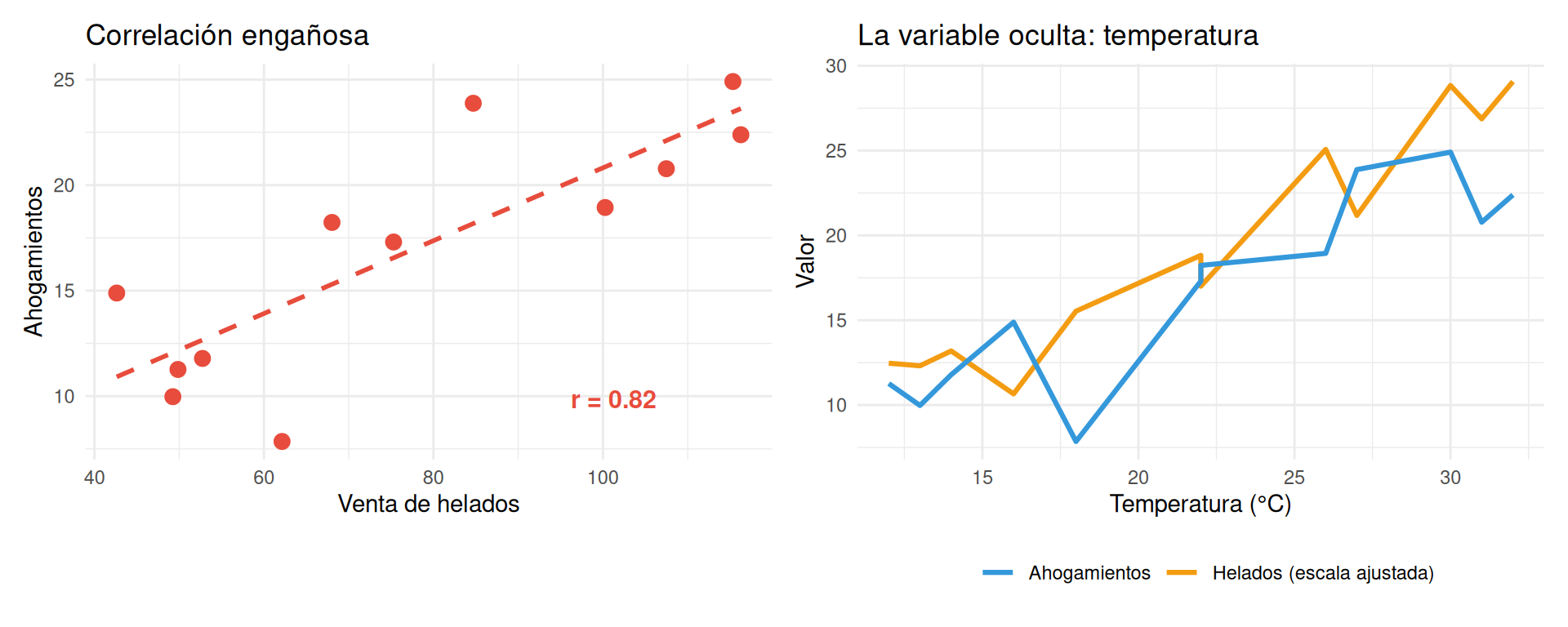
- Correlación ≠ causalidad. Esto debería estar tatuado en el brazo de todo investigador. El consumo de helado se correlaciona con los ahogamientos. ¿El helado causa ahogamientos? No. Ambos aumentan en verano. Hay una tercera variable (la temperatura) que los explica.
13.4.2 Regresión
La regresión es la herramienta más usada en ciencias sociales cuantitativas. Permite estimar el efecto de una o más variables independientes sobre una variable dependiente, controlando por otras variables.
Regresión lineal (OLS): Para variables dependientes continuas (ingreso, puntaje de prueba, años de educación). Es el caballo de batalla. Si dominas una sola técnica, que sea esta. Wooldridge lo explica con gran claridad en su texto de econometría (Wooldridge, 2020).
Regresión logística: Para variables dependientes binarias (desertar/no desertar, votar/no votar, estar de acuerdo/no). Los coeficientes no se interpretan directamente como en OLS —necesitas convertirlos a odds ratios o probabilidades predichas.
Regresión multinivel (modelos jerárquicos): Para datos jerárquicos: estudiantes dentro de escuelas, escuelas dentro de distritos, distritos dentro de regiones. Si ignoras la estructura jerárquica, subestimas los errores estándar y te engañas sobre la significancia.
Regresión con datos de panel: Combina la variación entre unidades (cross-section) con la variación en el tiempo (serie temporal). Los modelos de efectos fijos son especialmente poderosos porque controlan todas las características fijas de cada unidad, observables y no observables.
13.4.3 Guía rápida: ¿qué test necesito?
| Tu situación | Técnica sugerida | ¿Para qué sirve? |
|---|---|---|
| Comparar medias de 2 grupos | t de Student | ¿Los hombres y las mujeres ganan diferente? |
| Comparar medias de 3+ grupos | ANOVA | ¿Hay diferencias de ingreso entre regiones? |
| Relación entre 2 variables continuas | Correlación de Pearson | ¿A más años de educación, más ingreso? |
| Relación entre 2 variables ordinales | Correlación de Spearman | ¿A mayor nivel educativo, mayor satisfacción? |
| Predecir variable continua | Regresión lineal | ¿Cuánto afecta la educación al ingreso, controlando por edad? |
| Predecir variable binaria | Regresión logística | ¿Qué factores predicen la deserción escolar? |
| Datos con estructura jerárquica | Modelos multinivel | ¿Cuánto del rendimiento se explica por la escuela vs. el estudiante? |
| Datos en el tiempo | Series de tiempo / Panel | ¿Cómo cambió el efecto de una política a lo largo de los años? |
| Datos con variable de conteo | Poisson / Binomial negativa | ¿Qué factores predicen el número de hijos? |
13.4.4 Lo que la regresión NO te dice
Un resultado “estadísticamente significativo” (p < 0.05) no significa que sea importante en la vida real. Puedes tener un efecto estadísticamente significativo pero sustantivamente irrelevante: un programa que mejora las notas en 0.01 puntos con p < 0.001. Con una muestra suficientemente grande, todo sale significativo.
La American Statistical Association publicó un comunicado histórico en 2016 advirtiendo contra el uso mecánico del p-value (Wasserstein & Lazar, 2016). Sus puntos principales:
- Los p-values no miden la probabilidad de que la hipótesis sea verdadera.
- Un p-value de 0.05 no significa que haya un 95% de probabilidad de que el efecto sea real.
- La significancia estadística y la relevancia práctica son cosas completamente diferentes.
- Un p > 0.05 no significa que “no hay efecto.” Significa que tus datos no te permiten descartar la hipótesis nula con ese umbral.
ImportanteReflexión
Reporta siempre: (1) el tamaño del efecto, no solo su significancia; (2) los intervalos de confianza, no solo el p-value; y (3) una interpretación sustantiva de lo que el número significa en la vida real. “El programa aumentó las calificaciones en 3 puntos (IC 95%: 1.5 - 4.5, p < 0.01)” te dice más que “el efecto fue significativo.”
13.4.5 Los supuestos que nadie verifica (pero deberían)
Cada test estadístico tiene supuestos. Si los violas, tus resultados pueden ser desde ligeramente imprecisos hasta completamente falsos. Los más comunes en regresión lineal:
Linealidad: La relación entre X e Y es lineal. Si es curvilínea, tu modelo lineal te dará resultados engañosos. Solución: Gráfico de dispersión antes de cualquier regresión. Si la nube de puntos parece una curva, necesitas transformar variables o usar un modelo no lineal.
Homocedasticidad: La varianza del error es constante. Si los residuos se “abren” como abanico al aumentar X, tienes heterocedasticidad. Solución: Errores estándar robustos (casi siempre deberías usarlos por defecto).
No multicolinealidad: Tus variables independientes no están altamente correlacionadas entre sí. Si metes en la misma regresión “años de educación” y “nivel educativo,” estás midiendo casi lo mismo. Solución: Revisa la correlación entre tus independientes. VIF > 10 es señal de alarma.
Normalidad de los residuos: Los errores se distribuyen normalmente. Menos importante de lo que te enseñaron: con muestras grandes, la regresión es robusta a violaciones de normalidad.
Independencia de las observaciones: Cada caso es independiente de los demás. Si tus datos son de estudiantes en escuelas, los estudiantes de la misma escuela NO son independientes. Solución: Modelos multinivel o errores clustered.
No verificar estos supuestos es como tomar un medicamento sin leer las contraindicaciones. Puede que no pase nada. Puede que sí.
13.5 Análisis cualitativo: codificación, interpretación y rigor
El análisis cualitativo es tan riguroso como el cuantitativo —o debería serlo. La diferencia es que la herramienta no es la estadística sino la interpretación sistemática. Pero “interpretación” no significa “opinión.” Significa analizar datos textuales (entrevistas, observaciones, documentos) de forma organizada, transparente y fundamentada.
13.5.1 El análisis temático: paso a paso
Braun y Clarke publicaron en 2006 una guía que se convirtió en referencia obligada para el análisis temático (Braun & Clarke, 2006). Sus seis fases son claras y aplicables:
Familiarización: Lee y relee todo el material. Sumérgete. Anota impresiones iniciales, pero no codifiques aún. Este paso es como mirar los ingredientes antes de cocinar.
Codificación inicial: Asigna etiquetas (códigos) a fragmentos de texto que representen ideas, conceptos o patrones. Sé específico: no uses códigos vagos como “interesante” o “importante.” “Sentimiento de no pertenecer” es un código; “cosas sobre identidad” no lo es.
Búsqueda de temas: Agrupa los códigos en temas más amplios. Los códigos “sentimiento de no pertenecer,” “ser el primero de la familia en la universidad,” y “sensación de ser impostor” pueden agruparse bajo el tema “identidad y pertenencia.”
Revisión de temas: Verifica que cada tema está bien respaldado por los datos. ¿Hay suficientes extractos? ¿Los extractos realmente dicen lo que el tema afirma? Aquí es donde muchos fallan: crean un tema que suena bonito pero que solo tiene 2 citas débiles de respaldo.
Definición y nombramiento: Dale a cada tema un nombre claro y una definición precisa. ¿De qué trata este tema exactamente? ¿Qué incluye y qué no?
Escritura: El análisis no termina cuando identificas los temas. Termina cuando los escribes de forma coherente, con evidencia suficiente, conectándolos con tu pregunta y tu marco teórico.
13.5.2 Análisis de contenido
Krippendorff define el análisis de contenido como “una técnica de investigación para hacer inferencias replicables y válidas a partir de textos” (Krippendorff, 2019). La clave está en “replicables”: otro investigador, usando las mismas reglas de codificación, debería llegar a resultados similares.
El análisis de contenido puede ser:
- Cuantitativo: Contar frecuencias. ¿Cuántas veces aparece el tema “violencia” en los discursos presidenciales? ¿En qué proporción los medios cubren positiva vs. negativamente a un candidato?
- Cualitativo: Interpretar significados. ¿Cómo se construye la narrativa de “seguridad” en los discursos? ¿Qué metáforas se usan?
- Mixto: Ambos. Primero cuentas, luego interpretas (o viceversa).
Lo que distingue al análisis de contenido de simplemente “leer textos” es la sistematicidad: defines categorías antes de analizar, entrenas codificadores, mides la confiabilidad entre codificadores (¿dos personas independientes codifican igual?), y reportas los resultados de forma replicable.
13.5.3 Otros enfoques cualitativos
Miles, Huberman y Saldaña ofrecen un compendio exhaustivo de técnicas de análisis cualitativo que va mucho más allá del análisis temático (Miles et al., 2014):
- Análisis narrativo: Se enfoca en las historias que cuentan los participantes. No solo qué dicen, sino cómo lo cuentan: la estructura narrativa, los giros, los silencios, los protagonistas.
- Teoría fundamentada (Grounded Theory): Genera teoría a partir de los datos (en vez de verificar teoría existente). Es más ambiciosa y más exigente que el análisis temático.
- Análisis del discurso: Examina cómo el lenguaje construye realidades sociales. No busca “lo que la gente piensa” sino “cómo el lenguaje produce ciertos efectos.”
- Fenomenología: Busca la esencia de una experiencia vivida. ¿Qué es la experiencia de migrar? No las causas ni las consecuencias, sino la experiencia misma.
13.5.4 El peligro del “cherry picking”
Seleccionar solo las citas que confirman tu argumento es el pecado capital del análisis cualitativo. Si de 20 entrevistados, 15 dicen una cosa y 5 dicen otra, los 5 también importan. Tu trabajo es mostrar la complejidad, no la simplicidad.
Algunos indicadores de cherry picking:
- ❌ Solo citas de 3 de tus 20 entrevistados.
- ❌ Las mismas personas citadas una y otra vez.
- ❌ Todos los extractos refuerzan la misma conclusión; ninguno la matiza o la contradice.
- ❌ No se menciona cuántos participantes expresaron cada tema.
Lo que deberías hacer:
- ✅ Indicar cuántos participantes mencionaron cada tema.
- ✅ Incluir “casos negativos” (los que no encajan en el patrón).
- ✅ Citar a participantes diversos, no solo a los más elocuentes.
- ✅ Ser transparente cuando un tema es fuerte (mencionado por 18 de 20) vs. emergente (mencionado por 3 de 20).
13.5.5 Software para análisis cualitativo
| Software | Fortalezas | Debilidades | ¿Para quién? |
|---|---|---|---|
| NVivo | Muy completo, visualizaciones potentes | Costoso, curva de aprendizaje pronunciada | Investigadores con proyectos grandes |
| Atlas.ti | Interfaz intuitiva, buen manejo de multimedia | Costoso | Proyectos medianos a grandes |
| MAXQDA | Mezcla cuali y cuanti, excelente para métodos mixtos | Menos conocido, costoso | Investigadores mixtos |
| Dedoose | Basado en web, relativamente económico | Menos potente | Estudiantes, proyectos pequeños |
| Excel | Gratuito, universal | No diseñado para esto, pero funciona | Tesis con 10-20 entrevistas |
| R (RQDA/qualitativeR) | Gratuito, reproducible | Requiere programación | Los valientes |
NotaPara recordar
El software organiza tus datos y facilita la codificación, pero no hace el análisis por ti. No importa cuánto cueste tu software: si tus códigos son vagos, tus temas son superficiales, y tu interpretación es perezosa, el resultado será malo. Un investigador hábil con Excel produce mejor análisis que un investigador mediocre con NVivo.
13.6 La gran comparación: herramientas cuantitativas
| Software | Fortalezas | Debilidades | Costo |
|---|---|---|---|
| R | Gratuito, flexible, reproducible, enorme ecosistema de paquetes | Curva de aprendizaje brutal, interfaz austera | Gratis |
| Stata | Estándar en economía y ciencias políticas, excelente para panel data | Costoso, comunidad más pequeña | $\[$ | | **SPSS** | Interfaz amigable, popular en psicología y educación | Limitado para técnicas avanzadas, costoso | \]$ |
| Python | Gratuito, versátil (no solo estadística), machine learning | No diseñado específicamente para estadística social | Gratis |
| Jamovi / JASP | Gratuitos, interfaz gráfica, reportan en APA | Limitados para análisis avanzados | Gratis |
| Excel | Universal, todo el mundo lo tiene | NO es software estadístico. Por favor, no hagas regresiones en Excel. | Incluido en Office |
¿Mi recomendación? Si estás empezando y quieres un camino fácil, Jamovi es sorprendentemente bueno para lo básico. Si quieres invertir en tu futuro, aprende R —es difícil al principio pero te abrirá puertas que SPSS nunca podrá. Si estás en economía, Stata es probablemente inevitable. Y si vienes del mundo tech o quieres hacer machine learning, Python con pandas y statsmodels.
Lo que no te recomiendo: usar Excel para análisis estadístico. Puedes usarlo para organizar datos, pero los cálculos estadísticos de Excel son limitados y a veces incorrectos. Si alguna vez te dicen “corre esta regresión en Excel,” huye.
13.7 Visualización de datos: un buen gráfico vale más que mil tablas
La visualización no es decoración. Es comunicación. Un buen gráfico puede transmitir instantáneamente lo que una tabla de 50 filas no puede. Este tema es tan importante que le dedicamos un capítulo entero (ver (visualizacion?)), pero aquí van los principios básicos:
13.7.1 Principios básicos
- Simplicidad: Menos es más. Elimina todo lo que no comunica información (gridlines innecesarias, 3D, efectos de sombra, leyendas obvias).
- Honestidad: No manipules ejes, escalas o colores para exagerar diferencias. Un eje Y que empieza en 98 en vez de 0 convierte una diferencia trivial en una aparente catástrofe.
- Propósito: Cada gráfico debe responder una pregunta. Si no sabes cuál, no lo incluyas.
- Legibilidad: Si tu lector necesita un máster en estadística para entender tu gráfico, hiciste algo mal. Un buen gráfico se entiende en 5 segundos.
13.7.2 Tipos de gráficos por uso
| Propósito | Gráfico recomendado | Gráfico a evitar |
|---|---|---|
| Distribución de una variable | Histograma, boxplot, violín | Gráfico de pastel |
| Relación entre dos variables | Diagrama de dispersión | Doble eje Y (confuso) |
| Comparar grupos | Barras (horizontales si hay muchos) | Barras 3D |
| Cambio en el tiempo | Línea temporal | Barras (cuando hay muchos períodos) |
| Composición | Barras apiladas al 100% | Gráfico de pastel con 15 categorías |
| Datos geográficos | Mapas temáticos (coropletas) | Tablas con nombres de regiones |
TipEjercicio
Antes de analizar tus datos, responde estas preguntas:
- Plan de análisis: Para cada objetivo específico de tu investigación, ¿qué técnica de análisis vas a usar? Escríbelo en una tabla: Objetivo → Variable(s) → Técnica → Software.
- Descriptivos primero: Corre análisis descriptivos completos antes de cualquier otra cosa. Medias, medianas, desviaciones estándar, frecuencias, tablas cruzadas. Mira tus datos.
- Tres gráficos: Haz al menos 3 gráficos que resuman tus hallazgos principales. Muéstralos a alguien sin contexto. ¿Entienden el mensaje? Si no, rediseña.
- Supuestos: Si vas a usar regresión, verifica los supuestos. Haz el gráfico de residuos. Calcula el VIF. No te saltes esto.
- Si es cualitativo: ¿Cuántas rondas de codificación hiciste? ¿Tienes un libro de códigos? ¿Alguien más revisó tu codificación? Si la respuesta a las tres es “no,” tu análisis necesita más trabajo.
Braun, V., & Clarke, V. (2006). Using Thematic Analysis in Psychology. Qualitative Research in Psychology, 3(2), 77-101.
Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). SAGE Publications.
Krippendorff, K. (2019). Content Analysis: An Introduction to Its Methodology (4th ed.). SAGE Publications.
Miles, M. B., Huberman, A. M., & Saldaña, J. (2014). Qualitative Data Analysis: A Methods Sourcebook (3rd ed.). SAGE Publications.
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA Statement on p-Values: Context, Process, and Purpose. The American Statistician, 70(2), 129-133.
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for Data Science (2nd ed.). O’Reilly Media. https://r4ds.hadley.nz/
Wooldridge, J. M. (2020). Introductory Econometrics: A Modern Approach (7th ed.). Cengage Learning.