11 Muestreo: ¿a quién le preguntas?
11.1 La pregunta que define tu credibilidad
Puedes tener la mejor pregunta, el mejor marco teórico y el mejor instrumento. Pero si le preguntas a las personas equivocadas (o a muy pocas, o a muy homogéneas), tus resultados no valen mucho.
El muestreo es, en esencia, una decisión sobre a quién estudias y cómo los seleccionas. Y esa decisión determina qué tan generalizables, creíbles y útiles son tus conclusiones. Como señala Cochran (1977), un buen diseño muestral no es un lujo estadístico; es lo que separa la evidencia del ruido.
11.2 Población y muestra: lo básico
- Población (o universo): El grupo total que te interesa estudiar. “Todos los estudiantes universitarios de primer año en Perú.”
- Muestra: El subconjunto de esa población que efectivamente estudias. “500 estudiantes de primer año de 5 universidades públicas de Lima.”
- Marco muestral: La lista concreta de donde sacas tu muestra. “El registro de matrícula 2025 de las 5 universidades seleccionadas.” Sin marco muestral, no hay muestreo probabilístico posible.
Casi nunca puedes estudiar a toda la población (salvo que sea muy pequeña, lo que se llama censo). Por eso seleccionas una muestra y, a partir de ella, haces inferencias sobre la población.
La clave: tu muestra debe representar a tu población. Si tu muestra está sesgada, tus conclusiones están sesgadas. Así de simple y así de grave.
11.2.1 La población accesible vs. la población objetivo
Una distinción que pocos manuales hacen y que es crucial:
- Población objetivo: A quiénes quieres estudiar. “Todos los emprendedores informales de Lima.”
- Población accesible: A quiénes puedes acceder. “Los emprendedores informales del mercado central de Gamarra que están dispuestos a responder una encuesta.”
La brecha entre ambas es casi siempre enorme. Y esa brecha es una limitación que debes reconocer explícitamente.
11.3 Muestreo probabilístico: el ideal (cuando se puede)
En el muestreo probabilístico, cada individuo de la población tiene una probabilidad conocida (y no nula) de ser seleccionado. Esto permite hacer inferencias estadísticas y generalizar los resultados con un margen de error calculable.
11.3.1 Aleatorio simple
Cada individuo tiene la misma probabilidad de ser seleccionado. Como una lotería justa. - Ventaja: Máxima representatividad (en teoría). Es el ideal contra el que se comparan todos los demás métodos. - Problema: Necesitas un listado completo de tu población (marco muestral). ¿Tienes una lista de TODOS los emprendedores informales de tu ciudad? Probablemente no. Y si la tienes, probablemente está incompleta o desactualizada.
11.3.2 Sistemático
Seleccionas cada k-ésimo elemento de una lista. Por ejemplo, de una lista de 10.000 estudiantes, seleccionas uno de cada 20 (k = 10.000 / 500 = 20). Empiezas con un número aleatorio entre 1 y 20, y luego saltas de 20 en 20. - Ventaja: Más fácil de implementar que el aleatorio simple. No necesitas numerar toda la lista. - Peligro: Si la lista tiene un patrón cíclico que coincida con tu intervalo de selección, puedes generar un sesgo. (Raro, pero hay que saberlo.)
11.3.3 Estratificado
Divides la población en subgrupos (estratos) y seleccionas aleatoriamente dentro de cada uno. - Ejemplo: Quieres asegurarte de tener representación de universidades públicas y privadas, así que muestreas aleatoriamente dentro de cada estrato. - Ventaja: Garantiza representación de subgrupos importantes. Puede ser más eficiente que el aleatorio simple (menor margen de error con el mismo n). - Variante: El estratificado proporcional (cada estrato aporta casos proporcional a su peso en la población) vs. el estratificado desproporcional (sobrerepresentas estratos pequeños para poder analizarlos). Si usas desproporcional, necesitas ponderar al analizar.
11.3.4 Por conglomerados
Divides la población en grupos naturales (escuelas, barrios, empresas) y seleccionas algunos grupos al azar, y dentro de ellos estudias a todos (o una muestra). - Ejemplo: Seleccionas 20 escuelas al azar de un universo de 200, y encuestas a todos los estudiantes de esas 20 escuelas. - Ventaja: Más práctico y económico que el aleatorio simple. No necesitas un marco muestral de todos los individuos, solo de los conglomerados. - Desventaja: Mayor margen de error (los conglomerados pueden ser internamente homogéneos). Necesitas un efecto de diseño (DEFF) para corregir.
11.3.5 Multietápico
Combinación de los anteriores en varias etapas. Es lo que usan las encuestas nacionales como ENAHO (Perú) o CASEN (Chile). - Ejemplo: Primera etapa: seleccionar distritos al azar (conglomerados). Segunda etapa: dentro de cada distrito, seleccionar manzanas al azar. Tercera etapa: dentro de cada manzana, seleccionar viviendas al azar. Cuarta etapa: dentro de cada vivienda, seleccionar un adulto al azar. - Ventaja: Factible a escala nacional sin un marco muestral de toda la población. - Desventaja: Acumula error en cada etapa. El diseño y el cálculo de errores son complejos.
11.3.6 Tabla resumen: muestreo probabilístico
| Tipo | Requisito | Ventaja principal | Limitación principal | Cuándo usarlo |
|---|---|---|---|---|
| Aleatorio simple | Marco muestral completo | Máxima representatividad | Impráctico con poblaciones grandes | Poblaciones pequeñas y accesibles |
| Sistemático | Lista ordenada | Fácil de implementar | Riesgo de periodicidad | Alternativa al aleatorio simple |
| Estratificado | Conocer los estratos | Representación garantizada de subgrupos | Necesitas conocer la estructura de la población | Cuando hay subgrupos relevantes |
| Conglomerados | Grupos naturales | Económico, no necesita marco individual | Mayor margen de error | Poblaciones geográficamente dispersas |
| Multietápico | Varios marcos por etapa | Factible a gran escala | Complejo, acumula error | Encuestas nacionales |
11.4 Muestreo no probabilístico: la realidad
Seamos honestos: la mayoría de las tesis en ciencias sociales usan muestreo no probabilístico. No porque sea ideal, sino porque las condiciones para el probabilístico rara vez se cumplen (no hay listados completos, no hay recursos, no hay tiempo).
Eso no significa que valga todo. Hay muestreos no probabilísticos mejores y peores.
11.4.1 Por conveniencia
Estudias a los que tienes a la mano. “Encuesté a mis compañeros de clase.” - Problema: Es el muestreo más débil. No puedes generalizar. Pero a veces es lo único posible (y eso hay que reconocerlo honestamente). - Cuándo es aceptable: Estudios piloto, pruebas de instrumentos, investigaciones exploratorias donde no pretendes generalizar.
11.4.2 Bola de nieve (snowball)
Un participante te lleva a otro. Ideal para poblaciones difíciles de alcanzar (hidden populations). - Ejemplo: Investigas migración indocumentada. No hay un listado de personas en esa situación. Pero si contactas a una, ella te conecta con otras. - Problema: Sesgo de red (llegas a personas conectadas entre sí, no a las aisladas). Sobrerepresentas a los más sociables y conectados. - Mejora posible: Respondent-Driven Sampling (RDS), que añade correcciones estadísticas a la bola de nieve.
11.4.3 Intencional (o por juicio / purposive)
Seleccionas casos deliberadamente porque son informativos para tu investigación. Es el muestreo estrella de la investigación cualitativa. - Ejemplo: Para un estudio de caso sobre liderazgo educativo, eliges a la directora que transformó una escuela en crisis. - Fortaleza: Profundidad y relevancia del caso. Como dice Patton (2015), el poder del muestreo intencional reside en seleccionar casos ricos en información para estudio en profundidad. - Debilidad: Tu criterio puede estar sesgado. La selección debe ser transparente y justificada.
Subtipos del muestreo intencional (siguiendo a Patton (2015)):
| Subtipo | Lógica | Ejemplo |
|---|---|---|
| De variación máxima | Capturar diversidad | Seleccionar escuelas urbanas/rurales, grandes/pequeñas, exitosas/fracasadas |
| De casos homogéneos | Profundizar en un subgrupo | Solo madres adolescentes de primer hijo |
| De caso típico | Representar lo “normal” | Una escuela que representa el promedio nacional |
| De caso extremo o desviante | Entender la excepción | El país pobre con alta expectativa de vida |
| De caso crítico | Testear teoría | “Si funciona aquí, funciona en cualquier lado” |
| De criterio | Cumplir un estándar | Todos los que hayan participado en el programa por al menos 2 años |
11.4.4 Por cuotas
Similar al estratificado, pero sin aleatorización. Defines cuántas personas de cada grupo necesitas y las buscas activamente. - Ejemplo: Necesitas 50 hombres y 50 mujeres, 25 de cada nivel socioeconómico. - Ventaja: Garantiza diversidad demográfica mínima. - Problema: Dentro de cada cuota, la selección no es aleatoria (¿a cuáles 50 mujeres accedes?).
11.5 El tamaño de muestra: la pregunta que todos hacen
“¿Cuántas personas necesito?” es la pregunta que más me hacen. Y la respuesta honesta es: depende.
11.5.1 Para estudios cuantitativos
El tamaño de muestra depende de:
- El tamaño de la población (N). Importa menos de lo que crees: con poblaciones mayores a 10.000, el tamaño de muestra necesario es prácticamente el mismo que con un millón.
- El nivel de confianza deseado (generalmente 95%, que corresponde a z = 1.96).
- El margen de error aceptable (generalmente 5%).
- La variabilidad del fenómeno (p). Si no sabes, asume p = 0.5 (máxima variabilidad, escenario más conservador).
- El tipo de análisis estadístico. Una regresión múltiple con 10 predictores necesita más casos que una correlación simple.
La fórmula clásica de Cochran (1977) para proporciones es:
\[n = \frac{z^2 \cdot p \cdot (1-p)}{e^2}\]
Donde \(z\) = valor z del nivel de confianza (1.96 para 95%), \(p\) = proporción esperada, y \(e\) = margen de error. Para poblaciones finitas, se aplica un factor de corrección:
\[n_{corr} = \frac{n}{1 + \frac{n-1}{N}}\]
Reglas prácticas (no sustituyen el cálculo, pero orientan):
| Tipo de análisis | Mínimo recomendado |
|---|---|
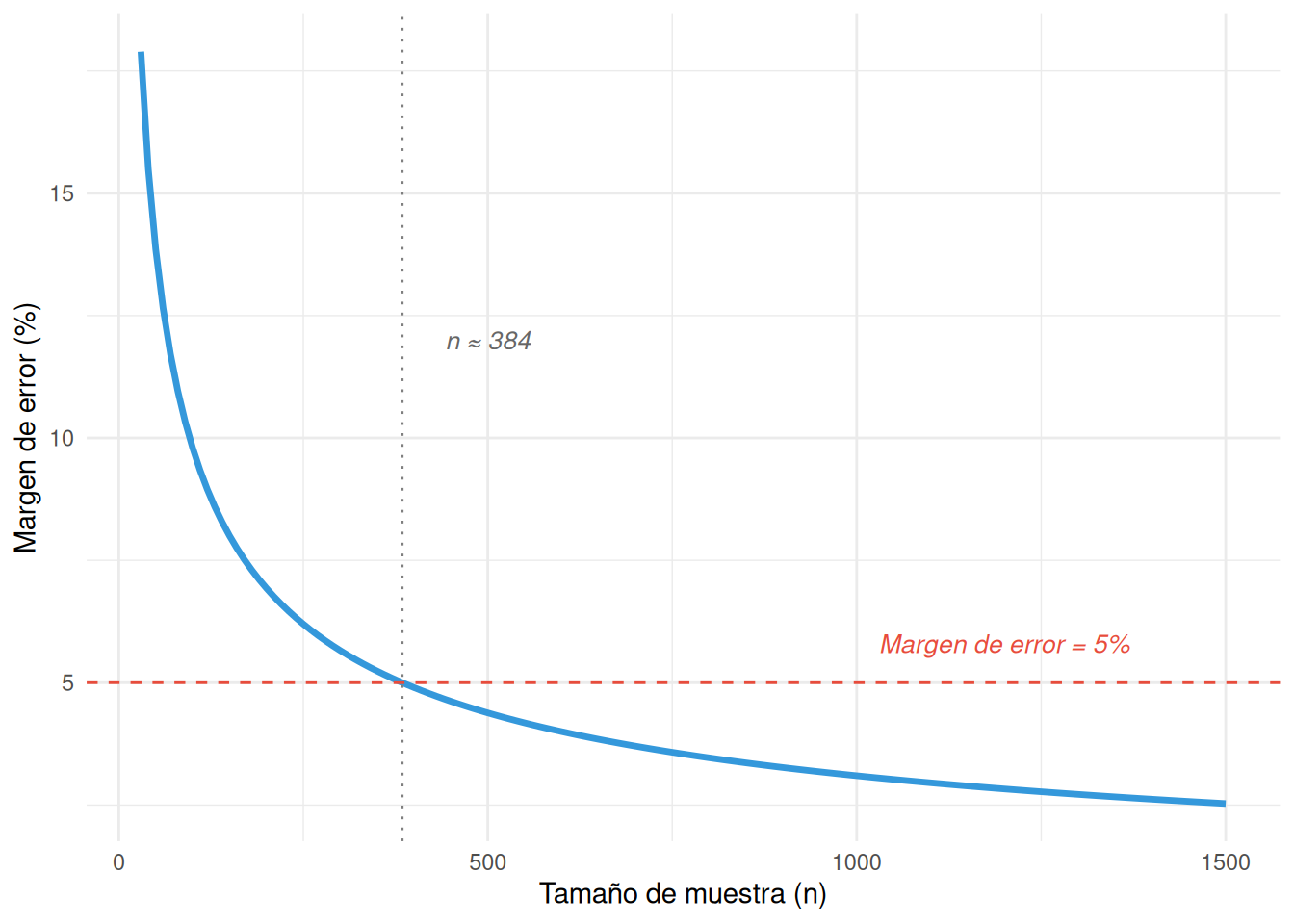
| Encuesta descriptiva, población grande | 384 (con 95% confianza, 5% error, p = 0.5) |
| Correlación | 30-50 por variable |
| Regresión múltiple | 10-20 casos por predictor (mínimo 50 en total) |
| Análisis factorial | 300+ (o 10 casos por ítem) |
| Comparación de 2 grupos (t-test) | 30 por grupo (mínimo) |
| ANOVA | 20-30 por grupo |
Nota cómo a partir de cierto punto, aumentar la muestra tiene rendimientos decrecientes. Pasar de 100 a 400 casos reduce enormemente el margen de error. Pero pasar de 400 a 1.000 apenas lo mejora. Es la ley de rendimientos decrecientes aplicada al muestreo.
AdvertenciaCuidado con los calculadores mágicos
Hay cientos de calculadoras de tamaño de muestra en internet. Son útiles, pero peligrosas si no entiendes lo que están calculando. La fórmula de Cochran asume muestreo aleatorio simple. Si tu diseño es por conglomerados, necesitas multiplicar por el efecto de diseño (DEFF ≈ 1.5-2.0 típicamente). Si no haces este ajuste, tu muestra puede ser insuficiente.
11.5.2 Para estudios cualitativos
No hay fórmula. El criterio principal es la saturación teórica: cuando nuevas entrevistas o observaciones dejan de aportar categorías, temas o información nueva, has llegado al punto de saturación (Patton, 2015).
En la práctica:
| Técnica | Rango típico | Nota |
|---|---|---|
| Entrevistas en profundidad | 15-30 participantes | Depende de la heterogeneidad del grupo |
| Grupos focales | 3-6 grupos de 6-10 personas | Mínimo 3 para comparar |
| Observación participante | 1-3 contextos | Meses de inmersión |
| Estudio de caso | 1-5 casos | Profundidad sobre cantidad |
Pero son orientaciones, no reglas. Lo importante es poder justificar por qué ese número es suficiente para responder tu pregunta. Y la saturación debe ser demostrada, no solo declarada. (“Alcancé saturación con 12 entrevistas” → ¿Cómo lo sabes? ¿Qué encontraste en las entrevistas 10, 11 y 12 que ya habías encontrado antes?)
11.6 Los sesgos del muestreo: lo que puede salir mal
11.6.1 Sesgo de selección
Tu muestra no representa a tu población porque la forma de selección favorece a ciertos tipos de personas. Los que responden encuestas online no son los mismos que los que no tienen internet.
11.6.2 Sesgo de autoselección
Los que deciden participar son diferentes a los que no. Las personas más interesadas, más educadas, o más motivadas tienden a autoseleccionarse. El que responde una encuesta sobre satisfacción laboral probablemente tenga más opiniones (positivas o negativas) que el indiferente que la ignoró.
11.6.3 Sesgo de supervivencia
Solo estudias a los que “sobrevivieron.” Si investigas factores de éxito empresarial entrevistando a empresarios exitosos, nunca ves a los que fracasaron (y que quizás tenían los mismos factores). Es como estudiar agujeros de bala en aviones que regresaron de la guerra para decidir dónde blindar: los aviones que no regresaron son los que realmente necesitabas estudiar.
11.6.4 Sesgo de no respuesta
Los que no responden tu encuesta no son aleatorios. Suelen ser los más ocupados, los más pobres, los menos educados, los que desconfían. Si tu tasa de respuesta es del 30%, tienes un problema serio: ¿qué tienen de especial ese 30% que sí respondió?
11.7 El error que más veo: la muestra de conveniencia disfrazada
El error más común (y más deshonesto) es usar una muestra por conveniencia y presentarla como si fuera representativa.
“Seleccionamos una muestra aleatoria estratificada de…” No, no lo hiciste. Encuestaste a los que encontraste en el pasillo de tu facultad un martes a las 10 de la mañana. Y eso está bien si lo dices. Lo que no está bien es disfrazarlo.
La honestidad sobre las limitaciones de tu muestra no debilita tu investigación. La fortalece. Porque demuestra que entiendes lo que hiciste y lo que eso implica para la interpretación de tus resultados.
ImportanteReflexión
La calidad de tu muestra es un techo para la calidad de tus conclusiones. Una estadística sofisticadísima aplicada a una muestra basura produce basura sofisticada. No hay técnica de análisis que compense un muestreo deficiente. Invierte tiempo en diseñar tu muestreo antes de salir al campo.
TipEjercicio
Para tu investigación:
- Define tu población objetivo y tu población accesible. ¿Cuál es la brecha entre ambas?
- ¿Existe un marco muestral disponible? Si no, ¿puedes construir uno?
- ¿Puedes hacer muestreo probabilístico? Si no, ¿por qué no? (Sé honesto.)
- ¿Qué tipo de muestreo es más viable para tu caso? Justifícalo con argumentos prácticos y metodológicos.
- Calcula tu tamaño de muestra. Si es cuantitativo, usa la fórmula de Cochran (o una calculadora, pero entiende lo que calcula). Si es cualitativo, justifica con el criterio de saturación.
- ¿Qué sesgos podría tener tu muestra? Para cada sesgo identificado, ¿hay alguna estrategia para mitigarlo?
Cochran, W. G. (1977). Sampling Techniques (3rd ed.). John Wiley & Sons.
Patton, M. Q. (2015). Qualitative Research & Evaluation Methods: Integrating Theory and Practice (4th ed.). SAGE Publications.